위키백과에 적혀 있는 정의로는 다음과 같습니다.
-> '정규 표현식(正規表現式, 영어: regular expression, 간단히 regexp 또는 regex, rational expression) 또는 정규식(正規式)은 특정한 규칙을 가진 문자열의 집합을 표현하는 데 사용하는 형식 언어이다. 정규 표현식은 많은 텍스트 편집기와 프로그래밍 언어에서 문자열의 검색과 치환을 위해 지원하고 있으며, 특히 펄과 Tcl은 언어 자체에 강력한 정규 표현식을 구현하고 있다.'
많은 분들이 간과 하고 있습니다만 ( 저도 사실 몰랐음...;;; ) MS Word 또는 OpenOffice와 같은 현대의 텍스트 편집기와 워드프로세스의 찾기 및 찾아 바꾸기 기능에서도 정규표현식 기반으로 검색을 할 수 있다고 합니다. ( 사용은 안해봤네요.... 이글 정리한 다음 부터는 자주 사용해봐야 겠습니다 )
일단 정규 표현식 패턴의 종류들을 정리하고 파이썬에서 사용은 어떤식으로 하는지 예제를 보여주는 방식으로 정리를 해볼까 합니다.
문자열 안에서 전화번호를 찾고 싶다고 가정해봅시다. 보통은 3개의 숫자 - 3개 혹은 4개의 숫자 - 4개의 숫자 ( 000-000-0000 or 000-0000-0000 ) 으로 보통 되어 있습니다. 이러한 패턴과 일치하는 여부를 확인하는 파이썬 함수를 한번 만들어 보겠습니다.
( 여기에서 실행되는 소스는 Python3 기준으로 작성되어 있습니다. )
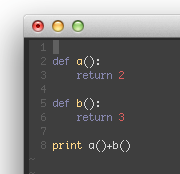
def isPhoneNumber(text):
if len(text) != 12 and len(text) != 13:
return False
for i in range(0, 3):
if not text[i].isdecimal():
return False
if text[3] != '-':
return False
if len(text) == 12:
for i in range(4, 7):
if not text[i].isdecimal():
return False
if text[7] != '-':
return False
for i in range(8, 12):
if not text[i].isdecimal():
return False
else:
for i in range(4, 8):
if not text[i].isdecimal():
return False
if text[8] != '-':
return False
for i in range(9, 13):
if not text[i].isdecimal():
return False
return True
message = 'Call me at 011-555-1011 tomorrow. 070-8888-8888 is my office.'
for i in range(len(message)):
chunk = message[i:i+12] << message 로 부터 12글자씩 나눠서 chunk변수에 할당 시킨다.
chunk1 = message[i:i+13] << message 로 부터 13글자씩 나눠서 chunk1변수에 할당 시킨다.
if isPhoneNumber(chunk): << 12글자를 담아서 전화번호의 패턴에 맞는지 확인한다. 맞으면 그 글자를 출력.
print('Phone Number found:' + chunk)
if isPhoneNumber(chunk1): << 13글자를 담아서 전호번호의 패턴에 맞는지 확인한다. 맞으면 그 글자를 출력.
print('Phone Number found:' + chunk1)
print('Done')
2가지의 경우만 나눴을 뿐인데 소스가 굉장히 지저분해집니다. 그리고 여기에 기준점이 또 추가 되거나 했을 경우에 더욱 코드가 많아 질 것 같습니다.
만약에 message 글자가 수백만 글자 길이 일수도 있고, 새로운 패턴이 있을 경우에 프로그램은 점점 더 무거워 질수 밖에 없습니다.
이러한 불편을 해결하기 위해서 정규표현식을 쓰면 코드를 더욱 간결하게 만들 수 있습니다.
일단 정규 표현식을 사용하기 위해서는 re모듈을 import 해주셔야 됩니다.
정규표현식을 나타내는 문자열 값을 re.complie()에 전달하면 Regex객체를 돌려받습니다.
phoneNumRegex = re.complie(r'\d\d\d-\d\d\d-\d\d\d\d) <<< (r'문자열') 을 원시 문자열이라 함. 원시 문자열로 하지 않게 되면 re.complie('\\d\\d\\d-\\d\\d\...') 설정.
해당 부분을 찾을 때는 다음과 같이 해주면 된다.
import re
phoneNumRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d')
mo = phoneNumRegex.search('My number is 415-555-5555.')
print('Phone Number found:' + mo.group())
결과값 : Phone Number found: 415-555-5555
소스코드가 매우 간단해졌습니다. 물론 4자리 관련된 부분은 생략되어 있지만 해당 작업은 추후에 다시 설명하도록 하겠습니다.
전화번호에서 지역번호를 분리하고 싶다고 했을 경우에 괄호를 추가하면 정규표현식에서 그룹이 만들어집니다. 모든 그룹을 한 번에 가져오려면 groups() 메소드를 사용하면 됩니다.
import re
phoneNumRegex = re.compile(r'(\d\d\d)-(\d\d\d-\d\d\d\d)')
mo = phoneNumRegex.search('My number is 415-555-5555.')
print(mo.group(1))
print(mo.group(2))
print(mo.group(0))
print(mo.group())
print(mo.groups())
areaCode, MainNumber = mo.groups()
print(areaCode)
print(MainNumber)
결과값
415
555-5555
415-555-5555
415-555-5555
('415', '555-5555')
415
555-5555
이때까지 3자리에 대한 부분만 살펴 보았습니다. 3자리와 4자리를 동시에 대조하려고 하면 어떻게 할 수 있을까요? 아주 간단합니다. '|' 기호만 사용하면 됩니다.
phoneNumRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d|\d\d\d-\d\d\d\d-\d\d\d\d')
mo = phoneNumRegex.search('My number is 415-555-5555, 000-1111-2222.')
print(mo.group())
결과값
415-555-5555
얼레? 이상합니다. 분명히 '|' 기호를 사용하면 된다고 했는데 왜 3자리 숫자만 나오는 걸까요? 그 이유는 search() 메소드가 패턴들 중에 처음으로 일치하는 결과값을 return해주기 때문입니다. 해결 방법은 다음과 같습니다.
phoneNumRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d|\d\d\d-\d\d\d\d-\d\d\d\d')
resultStr = phoneNumRegex.search('My number is 415-555-5555, 000-1111-2222.')
resultStr1 = phoneNumRegex.findall('My number is 415-555-5555, 000-1111-2222.')
print(resultStr.group())
print(resultStr1)
결과값
415-555-5555
['415-555-5555', '000-1111-2222']
이처럼 정규표현식을 사용하게 되면 복잡한 코드를 깔끔하게 정리 할 수 있게 됩니다. 다만 정규표현식을 모르면....
정규표현식에는 어떤 기능들이 더 있는지 살펴 보도록 하겠습니다.
<물음표(?)의 기능 >
지금까지 저희는 파이프('|')를 사용하여 문자 매칭을 하였습니다. 지금 사용하고 있는 정규 표현식을 좀 더 간단하게 하는 방법이 있습니다.
바로 '?' 기호인데요. ? 글자는 그 앞에 있는 그룹이 패턴의 선택적인 부분이라는 것을 뜻합니다. 무슨 소린지 잘 모르겠으니 다시 또 코드로 가겠습니다.
phoneNumRegex = re.compile(r'\d\d\d-\d\d\d\d?-\d\d\d\d')
resultStr = phoneNumRegex.findall('My number is 415-555-5555, 000-1111-2222.')
for result in resultStr:
print(result)
결과값
415-555-5555
000-1111-2222
보시는 바와 같이 정상적으로 잘 나옵니다. ?의 뜻은 위의 정규표현식은 마지막에 숫자가 없거나 한번 나타나는 텍스트와 일치 되는것입니다. 그러므로 저희가 위에서 사용한 파이프('|')를 사용한 정규표현식과 동일한 표현식이고 좀 더 코드가 간결해지겠군요.
<별표(*)의 기능>
* 표시는 "0개 또는 그이상과 일치"를 뜻합니다. 위에 정규 표현식을 또 줄일 수 있을 것 같습니다. 다음과 같이 말이죠.
phoneNumRegex = re.compile(r'\d\d\d-\d*-\d\d\d\d')
resultStr = phoneNumRegex.findall('My number is 415-555-5555, 000-1111-2222.')
for result in resultStr:
print(result)
결과값
415-555-5555
000-1111-2222
사실 정규 표현식을 re.compile(r'\d*-\d*-\d*') 라고 해도 됩니다. 그렇게 되면 이제 "숫자-숫자-숫자"의 모든 형식이 매칭 되겠죠 예를 들면 111111-2222222-3333333 또한 매칭이 됩니다. 상황에 맞게 조합을 해서 사용하면 좀 더 편하게 사용하실수 있겠네요.
<더하기기호(+)의 기능>
+ 기호는 "하나 이상과 일치"를 뜻합니다. 위의 코드 예제에서 * 대신에 +를 하게 되면 어떻게 될까요?
phoneNumRegex = re.compile(r'\d\d\d-\d+-\d\d\d\d')
하나 이상과 일치 되는 현상이기 때문에 두개의 번호가 전부 매칭이 됩니다.
다만 다음과 같이 하게 되면 어떻게 되는지는 고민해보시기 바랍니다.
phoneNumRegex = re.compile(r'\d\d\d-\d\d\d\d+-\d\d\d\d')
<중괄호({})의 기능>
특정한 횟수동안 반복되는 그룹이 있다면 정규식 안에 그 그룹뒤에 중괄호와 함께 횟수를 쓴다. 예를 들어 정규식 (Python){3}은 'PythonPythonPython' 문자열과는 일치 하지만 'PythonPython'과는 일치 하지 않습니다. (Python){3,5} 정규식은 'PythonPythonPython', 'PythonPythonPythonPython', 'PythonPythonPythonPythonPython'과 일치 합니다. 주의하실점은 파이썬의 정규표현식은 기본적으로 최대 일치입니다. 즉 모호한 상황에서는 가장 긴 문자열과 일치 시킵니다.
최소 일치를 원하실 경우에는 '(Python){3,5}?'를 입력하시면 됩니다. '?'는 정규표현식에서 두가지 의미를 지닙니다. 최소값의 일치를 의미할 수도 있고 위에서 사용한 선택적 그룹을 뜻할 수 도 있습니다. 문맥에 맞게 해석 하시면 됩니다.
<정규표현식의 문법>
문자 | 기능 |
. | 개행 문자를 제외한 1자를 나타냄 re.DOTALL이 설정되어 있으면, 개행을 포함한 문자1자를 나타냄 |
^ | 문자열의 시작을 나타냄 re.MULTILINE이 설정되어 있으면 매 라인마다 매치됨 |
$ | 문자열의 종료를 나타냄 re.MULTILINE이 설정되어 있으면 매 라인마다 매치됨 |
[] | 문자의 집합을 나타냄, 예를 들어 [abcd]의 경우 'a', 'b', 'c', 'd'중 한 문자와 매치됨 또한 문자의 집합을 [a-d]로도 나타낼수있음 또한 [^5]와 같이 '^'가 []안에서 쓰이는 경우에는 5를 제외한 모든 문자를 나타냄 또한 [$]와 같이 '$'가 []안에서 쓰이는 경우는 순수하게 '$'문자를 나타냄 |
| | 'A|B'와 같은 경우 'A' 혹은 'B'를 나타냄(OR연산) |
() | 괄호 안의 정규식을 구릅으로 만듬. 직접 '(', ')'(괄호)를 매칭시키기 위하여 '\(', '\)'나 '[(]', '[)]'로 나타냄 |
* | 문자가 0회 이상 반복됨을 나타냄 |
+ | 문자가 1회 이상 반복됨을 나타냄 |
? | 문자가 0회 혹은 1회 반복됨을 나타냄 |
{m} | 문자가 m회 반복됨을 나타냄 |
{m,n} | 문자가 m회부터 n회까지 반복되는 모든 경우를 나타냄 |
{m,} | 문자가 m회부터 무한 반복되는 모든 경우를 나타냄 |
<널리 쓰이는 짧은 버전의 문자 클래스>
짧은 문자 | 의미 |
\w | 문자, 숫자 글자, 또는 밑줄 글자. |
\W | 문자, 숫자 글자, 또는 밑줄 글자가 아닌 모든 글자. |
\d | 0에서 9까지의 임의의 숫자 글자 |
\D | 0에서 9까지의 숫자 글자가 아닌 모든 글자 |
\s | 빈칸, 탭(Tab), 또는 줄바꿈 문자. |
\S | 빈칸, 탭(Tab), 또는 줄바꿈 문자가 아닌 모든 글자 |
\b | 단어의 시작과 끝의 빈공백 |
\B | 단어의 시작과 끝이 아닌 빈공백 |
\\ | 역슬래시(\) 문자 자체를 의미 (문자열로 사용하지 못하는 문자의 경우 \? 이런식으로 해서 사용이 가능함.) |
\[숫자] | 지정된 숫자만큼 일치하는 문자열을 의미 |
\A | 문자열의 시작 |
\Z | 문자열의 끝 |













 입니다. 또 계산기를 두들겨 보면 다음과 같이 나옵니다.
입니다. 또 계산기를 두들겨 보면 다음과 같이 나옵니다.

 값이 0보다 크면 앞쪽에, 0보다 작으면 뒷쪽에 있는것으로 판별 합니다.
값이 0보다 크면 앞쪽에, 0보다 작으면 뒷쪽에 있는것으로 판별 합니다.
 로 정의하고
로 정의하고  로 정의를 하겠습니다. 세타의 값은
로 정의를 하겠습니다. 세타의 값은  일 때 내적의 정의는 다음과 같습니다.
일 때 내적의 정의는 다음과 같습니다.



 값은 점A에서 수선의 발을 내린점이 H라고 했을때 즉 선분 OH의 길이가 됩니다.
값은 점A에서 수선의 발을 내린점이 H라고 했을때 즉 선분 OH의 길이가 됩니다.

 벡터의 표현은 이런식으로 해줍니다.
벡터의 표현은 이런식으로 해줍니다. 이렇게 표현하면 벡터의 크기를 나타내주는 기호입니다. ( 절대값 표현 )
이렇게 표현하면 벡터의 크기를 나타내주는 기호입니다. ( 절대값 표현 ) 일때 이 벡터를
일때 이 벡터를  의 벡터를 편의상
의 벡터를 편의상  벡터라고 하면 역벡터는
벡터라고 하면 역벡터는  라고 표현하고 크기는 동일하지만 방향이 정반대인 벡터일 경우에 역벡터라고 정의합니다.
라고 표현하고 크기는 동일하지만 방향이 정반대인 벡터일 경우에 역벡터라고 정의합니다.







